Jak wykonać kopię zapasową lub przywrócić istniejące dane Redmine
Sukces każdego rozwiązania do zarządzania projektami opiera się na jednej prostej rzeczy - danych. Czy wiesz już, jak wykonać kopię zapasową lub przywrócić istniejące dane z Redmine? Jeśli nie, oto jak możesz to zrobić dla każdej bazy danych.

Kopie zapasowe Redmine muszą zawierać:
- Baza danych
- Załączniki (domyślnie umieszczane w katalogu plików poniżej katalogu instalacyjnego)
Tworzenie kopii zapasowych bazy danych
MySQL
MySQL, najpopularniejszy system baz danych Open Source SQL, jest unikalny, dystrybuowany i wspierany przez Oracle Corporation. Witryna MySQL zawiera najnowsze fakty dotyczące oprogramowania MySQL. MySQL może być urządzeniem zarządzającym.
Baza danych może być uporządkowaną serią statystyk. będzie to coś od prostej listy zakupów do galerii zdjęć lub znacznej ilości faktów w sieci firmowej. Aby dodawać, uzyskiwać dostęp i przetwarzać fakty przechowywane w bazie danych komputera, potrzebujesz urządzenia sterującego bazą danych obok MySQL Server. Ponieważ komputery doskonale radzą sobie z dużą ilością statystyk, systemy zarządzania odgrywają kluczową rolę w informatyce, jako samodzielne narzędzia lub jako składniki innych aplikacji. Bazy danych MySQL są relacyjne.
Elektroniczna baza danych przechowuje statystyki w oddzielnych tabelach, zamiast umieszczać wszystkie statystyki w jednym dużym magazynie. Struktury baz danych są przygotowywane w fizyczne dokumenty zoptymalizowane pod kątem szybkości. Model logiczny z gadżetami, w tym bazami danych, tabelami, widokami, wierszami i kolumnami, zapewnia giętkie środowisko programowania. Odkryłeś zasady rządzące relacjami między jednym a rodzajem pól informacyjnych, w tym jeden do jednego, jeden do wielu, unikalny, wymagany lub opcjonalny oraz „wskaźniki” między niezwykłymi tabelami.
Baza danych obsługuje te przepisy, a dzięki bardzo dobrze zaprojektowanej bazie danych twoje narzędzie w żadnym wypadku nie oznacza niespójnych, duplikatów, osieroconych, nieaktualnych lub brakujących statystyk. Składnik SQL „MySQL” oznacza „Structured Query Language”. SQL to najpopularniejszy język ustandaryzowany która chce uzyskać prawo dostępu do baz danych. licząc na swoje środowisko programistyczne, wpiszesz SQL bezpośrednio (na przykład, aby uzyskać raporty), osadzisz instrukcje SQL w kodzie napisanym w innym języku lub użyjesz specyficznego dla języka interfejsu API, który ukrywa składnię SQL. SQL jest opisany przy użyciu standardu ANSI/ISO SQL.
Oprogramowanie MySQL jest oprogramowaniem typu open source. Open Source oznacza, że każdy może używać i zmieniać oprogramowanie. Każdy może pobrać oprogramowanie MySQL z sieci i używać go bez płacenia. Jeśli chcesz, rzucisz okiem na kod dostępności i zmienisz go w zależności od potrzeb.
Oprogramowanie MySQL korzysta z rozszerzenia GPL (Powszechna Licencja Publiczna GNU), aby określić, co będziesz robić, a czego nie będziesz robić z oprogramowaniem w określonych sytuacjach. Jeśli odczuwasz dyskomfort z GPL lub chcesz osadzić kod MySQL w aplikacji biznesowej, kupisz od nas model licencjonowany komercyjnie.
Zobacz Omówienie licencjonowania MySQL więcej statystyk. Serwer bazy danych MySQL może być również szybki, niezawodny, skalowalny i płynny w użyciu. Jeśli tego właśnie szukasz, chciałbyś spróbować. MySQL Server może z łatwością działać na laptopie wraz z różnymi aplikacjami, serwerami sieciowymi itd., nie wymagając dużej uwagi lub wcale.
Jeśli zatwierdzisz cały system do MySQL, zmienisz ustawienia, aby wymagać wykorzystania całej dostępnej pamięci, mocy procesora i potencjału we/wy. MySQL może również skalować maksymalną ilość jako klastry maszyn połączonych w sieć. MySQL Server na początku ewoluował do obsługi dużych baz danych znacznie szybciej niż dotychczasowe rozwiązanies i od kilku lat jest skutecznie wykorzystywany w niezwykle niepokojących środowiskach produkcyjnych. Mimo ciągłego rozwoju, MySQL Server oferuje teraz ekskluzywny i cenny zbiór funkcji.
Jego łączność, szybkość i bezpieczeństwo sprawiają, że MySQL Server jest wyjątkowo idealny do uzyskiwania dostępu do baz danych w Internecie. MySQL Server działa w operacjach klient/serwer lub osadzonych. Oprogramowanie bazy danych MySQL może być maszyną patron/serwer, która: wielowątkowy serwer SQL który pomaga w wyjątkowym zapleczu, licznym wyjątkowym aplikacjom i bibliotekom konsumenckim, narzędziom administracyjnym i dobrym rodzajom interfejsów programowania narzędzi (API).
Jest bardzo prawdopodobne, że Twoje ulubione oprogramowanie lub język pomaga serwerowi bazy danych MySQL. Wymowa „MySQL” to „My Ess Que Ell” (nie „moja kontynuacja”), ale jest w porządku, jeśli wymawia się ją jako „moja kontynuacja” lub w inny zlokalizowany sposób.
Oto jak wykonać kopię zapasową danych dla My SQL:
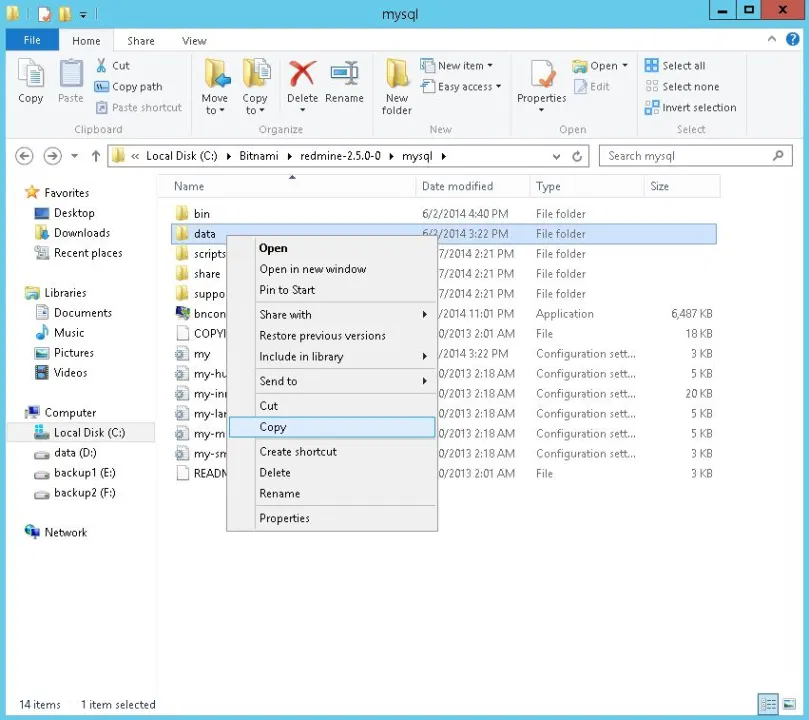
Polecenie mysqldump może służyć do tworzenia kopii zapasowych zawartości bazy danych MySQL w pliku tekstowym. Na przykład:
mysqldump -u -p > /path/to/backup/db/redmine.sql
Znajdź je , , , i w pliku config / database.yml. może nie być potrzebna w zależności od instalacji bazy danych.
PostgreSQL
PostgreSQL to wspaniały system zarządzania open source. Obsługuje każdy kod SQL dla zapytań relacyjnych i JSON dla zapytań nierelacyjnych. Jest wspierany przez doświadczoną społeczność programistów, którzy wnieśli niezwykły wkład, aby stworzyć z niego niezwykle niezawodny system DBMS. PostgreSQL obsługuje zaawansowane rodzaje danych i przyspiesza optymalizację wydajności, funkcje najlepiej dostępne w kosztownej biznesowej bazie danych, takiej jak Oracle i SQL Server.
MySQL czy PostgreSQL?
Wyzwanie MySQL sprawiło, że jego kod dostawczy był dostępny poniżej warunków licencji GNU i różnych umów własnościowych. PostgreSQL jest uruchamiany pod licencją PostgreSQL. Jest teraz własnością firmy Oracle Corporation i oferuje kilka płatnych edycji. Jest to oprogramowanie o otwartym kodzie źródłowym. Dzięki takiemu podejściu nigdy nie zapłacisz za tę usługę.
MySQL jest w najlepszym razie zgodny z ACID, gdy wykorzystuje się silniki NDB i InnoDB Cluster Storage PostgreSQL jest całkowicie zgodny z ACID. MySQL sprawdza się dobrze w strukturach OLAP i OLTP, gdzie liczy się tylko tempo nauki. Ogólna wydajność PostgreSQL działa zadowalająco w strukturach, które decydują o wykonywaniu skomplikowanych zapytań.
MySQL jest niezawodny i dobrze współpracuje z programami BI (Business Intelligence), które są trudne do odczytania PostgreSQL dobrze współpracuje z aplikacjami BI. Jest to jednak bardzo odpowiednie rozwiązanie dla hurtowni danych i pakietów ewaluacyjnych rekordów, które wymagają szybkich prędkości sprawdzania i zapisu.
Oto, jak możesz wykonać kopię zapasową danych dla PostgreSQL:
- Zaloguj się jako użytkownik postgres:
su - postgres - Użyj polecenia pg_dump, aby wykonać kopię zapasową całej zawartości bazy danych PostgreSQL do pliku tekstowego:
pg_dump -U -Fc <nazwa_bazy_danych>> / ścieżka/do/backup/db/redmine.sql
Znajdź je i w pliku config / database.yml. Polecenie pg_dump pomoże ci uzyskać dostęp do hasła, gdy będzie to wymagane.
SQLite
SQLite może być biblioteką oprogramowania, która daje elektroniczny gadżet do zarządzania bazą danych. Lite w podejściu SQLite jest lekkie pod względem konfiguracji, administrowania bazą danych i wymaganych zasobów. SQLite ma kolejne zauważalne możliwości: samowystarczalny, bezserwerowy, zerowej konfiguracji, transakcyjny. Bezserwerowe Zwykle RDBMS obok MySQL, PostgreSQL itp. wymaga do działania oddzielnego serwera.
Aplikacje wymagające wejścia na serwer bazy danych używają protokołu TCP/IP do wysyłania i odbierania żądań. Jest to często nazywane architekturą klient/serwer. Architektura RDBMS klient-serwer SQLite nie maluje w ten sposób. SQLite nie wymaga do działania serwera. Baza danych SQLite jest zintegrowana z urządzeniem, które uzyskuje dostęp do bazy danych.
Programy współpracują z bazą danych SQLite, aby przeglądać i pisać bezpośrednio z plików bazy danych zapisanych na dysku. Co to jest SQLite Samodzielny SQLite może być samodzielnym sposobem, który wymaga minimalnej pomocy ze strony gadżetu operacyjnego lub spoza biblioteki. To pokazuje, że SQLite jest pomocny w każdych okolicznościach, szczególnie w wbudowanych gadżetach, takich jak iPhone'y, telefony z systemem Android, konsole do gier, przenośne odtwarzacze multimedialne itp.. SQLite opracował wykorzystanie ANSI-C.
Plik tekstowy ASCII powinien mieć postać dużego pliku sqlite3.C, a jego raport nagłówkowy sqlite3.H. Jeśli chciałbyś poszerzyć narzędzie wykorzystujące SQLite, wystarczy, że wrzucisz te pliki do swojego projektu i zmontujesz je razem z kodem. Zerowa konfiguracja dzięki architekturze bezserwerowej, nie musisz „zainstalować” SQLite przed jego użyciem. nie ma żadnej procedury serwera, która musi być skonfigurowana, uruchomiona i zatrzymana. SQLite nie ćwiczy żadnych plików konfiguracyjnych. Wszystkie transakcje w SQLite są całkowicie zgodne z ACID.
Jego maniery i modyfikacje są atomowe, spójne, izolowane i wytrzymałe. Krótko mówiąc, wszystkie modyfikacje wewnątrz transakcji mają miejsce absolutnie lub w żadnych okolicznościach, nawet w przypadku nieoczekiwanego stanu rzeczy, takiego jak awaria zasilania, awaria zasilania lub awaria urządzenia operacyjnego. Funkcje wyróżniające SQLite SQLite używa dynamicznego sortowania tabel. Oznacza to, że utrzymasz dowolną cenę w dowolnej kolumnie, niezależnie od rodzaju statystyk. SQLite umożliwia jedno połączenie z bazą danych, aby wywołać odpowiedni wpis, aby jednocześnie wyciszyć jeden plik bazy danych.
Daje to wiele satysfakcjonujących funkcji, takich jak łączenie tabel w wyjątkowych bazach lub kopiowanie statystyk między bazami podczas jednego polecenia. SQLite jest w stanie tworzyć bazy danych w pamięci, które nie będą miały czasu na malowanie. Wszystkie bazy danych SQLite są zawarte w pliku, więc utworzysz ich kopię zapasową, kopiując plik do innej lokalizacji. Możesz określić nazwę pliku bazy danych SQLite, oglądając config/database.yml.
Tworzenie kopii zapasowych załączników
Każdy przesyłany plik jest przechowywany w ścieżce_przechowywania_ załączników (domyślnie jest to katalog pliki /). Możesz skopiować zawartość tego katalogu do innej lokalizacji, aby szybko wykonać kopię zapasową.
OSTRZEŻENIE: ścieżka_przechowywania załączników może wskazywać na specjalny katalog oprócz plików /. Pamiętaj, aby przejrzeć ustawienia w config / configuration.yml, aby uniknąć tworzenia bezużytecznej kopii zapasowej.
Przykładowy skrypt kopii zapasowej
Oto prosty skrypt powłoki, którego można używać do codziennych kopii zapasowych (zakładając, że korzystasz z bazy danych MySQL):
# Baza danych
/ usr / bin / mysqldump -u -p | gzip> / path / to / backup / db / redmine_`date +% Y-% m-% d`.gz
# Załączniki
rsync -a / ścieżka / do / redmine / files / path / to / backup / files
Przywróć bazę danych
MySQL
Na przykład, jeśli przechowujesz plik zrzutu zgzipowanego z tytułem 2018-07-30.gz, bazę danych można odzyskać za pomocą następującego polecenia:
gunzip <2018-07-30.gz | mysql -u -p
Wprowadź hasło.
PostgreSQL
Jeśli wybrano -Fc polecenia pg_dump, tak jak w powyższym przykładzie, chciałbyś użyć polecenia pg_restore:
pg_restore -U -re redmine.sql
Plik tekstowy można również przywrócić za pomocą psql:
psql <
SQLite
Skopiuj plik bazy danych z lokalizacji kopii zapasowej.
Najlepsza aktualizacja Redmine? Łatwo.
Uzyskaj wszystkie potężne narzędzia do doskonałego planowania, zarządzania i kontroli projektów w jednym oprogramowaniu.